让我们八一八机器学习加基因检测预测长相的这个刷屏帖的底
论文故事 --赤脚跑步有助于记忆力前几天,我被这样的一个帖子刷屏了,题目一看就是标题党,但其具体是怎么一回事了,这篇小文就来给你八一八这到底说的是什么?我们从这里可以看出,知识靠不靠谱,是需要去挖细节的,可不能听风就是雨。
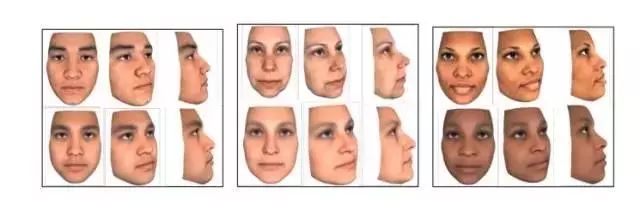
在这个帖子中,我们看到了这样的一副图,图中上面的是真实的面貌,下面的是机器学习的算法基于基因检测的结果预测出来的相貌,是不是很相似啊。
然而我们要问的第一个问题就是,这里列出的三个样本,有代表性吗?要知道这项研究有1061名参与者,作者完全可以选择三个看起来最好的结果放到这里的。这么想可不是我以小人之心度君子之腹,而是科学就是一个需要你来不断的质疑权威的过程,只要你有证据。
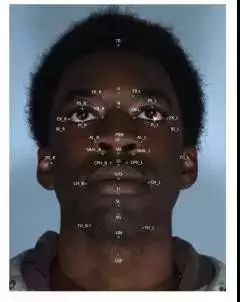
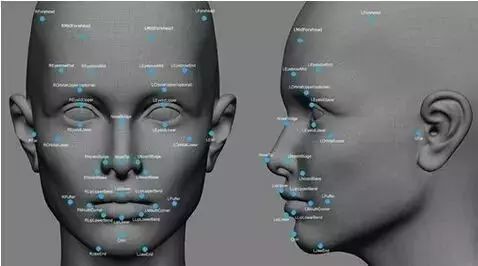
那怎么去找证据了,我们看一看作者是怎么做到这一步的。首先要问自己一个问题,人的长相,该怎么去量化。你会想到要对人脸进行扫描,但扫描之后,要怎么去做数据压缩了。这篇文章的作者给出的答案是在人脸的3D模型上标出36个点,如下图所示。
作者在文章的附加材料中详细的描述了这些点是按什么规则标记出来的,比如有的点是下巴最低的地方,有的是两眼的中间,而所有的这一千多个样本,都是由人手动去做标记的,唉,也不知是那个倒霉的博士生做的。从这里我们看到,当前的机器学习,还是大量的依赖人工去做数据清洗这类的体力活。
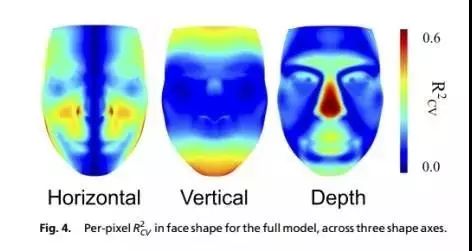
接着问题就转化成了通过基因信息预测3D模型上这些点之间的距离,以及预测肤色,眼睛的颜色这样的信息,这样问题就变得好解决,也好量化了。既然是3D模型,那么就有长宽高这三个维度,让我们来看看在这三个维度上,机器预测出来的结果和真实结果的相差多少(学术上称为皮尔森相关系数),这部分会有一些难,但不要怕,我会用很通俗的话来讲解。
这里展示的一张脸的三个维度上的投影,其中的颜色的不同代表不同区域预测结果和实际结果的相关系数,相关系数越高,预测就越准。注意这里是集合了所有样本的信息,我们看到,基因预测长相,预测最准的是鼻子的高矮,其次是尖下巴还是平下巴(这里是红色的,相关系数高),这符合我们的常识。但我们也要看到,图片上大面积的区域都是蓝色的,也就是说算法预测的和实际的结果关系不大。而这作者在文章中自己也承认。
而这也是我为什么在一开始的时候怀疑作者给出的那三幅图有cherry picking的嫌疑,也就是挑好的来展示的意思。毕竟即使是再不准确的表,每天也会有两次是对的。
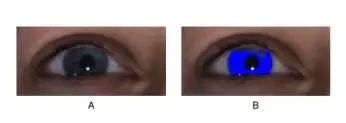
说完了对脸形的预测,我们再来说说肤色是怎么一回事。要拿到肤色的训练数据,我们也需要找出一张脸上,那些像素点能够代表这张脸的肤色。而这个问题就相比来说简单多了,因为有现成的方法,机器视觉已经将这个问题解决的足够好了,用卷积神经网络CNN就好了。从这里也可以看出,任何一个领域的研究,都需要依赖其他领域的进展,未来如果要做几十万人的类似研究,可不能再像上面那样手动的打标签啊。(下图所示是机器找出的代表眼睛颜色的像素点)
这篇文章中不止讲了用基因去预测长相,还讲了能用基因去预测年龄。在过好健康的一生 你需要守护你的端粒 中,介绍了DNA序列末端的端粒会随着人的衰老而变短,利用这一特性,可以从基因序列预测出受试者的年龄,但目前预测的不够准,平均的误差是8岁。不过这很正常,人不止有身份证上写的年龄,还有生理年龄,也就是说那些生活方式健康,压力又小的人生理年龄会比实际年龄要小,所以未来不管样本增加多少,通过基因去预测实际年龄都不会变得很准,但若是增加样本量,我们估计预测长相的准确度会提高。
除了长相,基因数据还被作者用来预测身高体重还有BMI这些指标,我们可以猜想,预测身高要更准确,预测体重要更难一些,而实际的数据也证实了我们最初的猜想,预测身高的平均误差为4.9cm,按平均身高1米7来算,也就差了3%,而预测体重的平均误差则为15.6KG,按一个人平均80公斤来算,查了接近20%了。
好了,这篇文章的主要内容就讲到这里,让我们思考一下,我们之前说了预测年龄时,通过基因数据(DNA末端的端粒长度)来预测是生理年龄,而不是实际年龄,而生理年龄又受生活习惯的影响。那么问题是,既然知道了受试者的体重,那么能不能将体重这一信息利用在对年龄的预测中了? 再加上我们有了个体基因预测的BMI和实际观察到的BMI,那么我们能不能推测那些实际BMI要原大于基因预测的BMI的样本,其超重是由于个人的生活习惯引起的,而这则会反映到其生理年龄要大于其实际年龄上了?这样的问题,也是这份数据可以回答的。阅读科学论文,就是要训练自己去问出好问题的能力。
总结一下,今天我们详细的看了看一篇爆款的科学新闻稿背后的故事,我们看到了不能盲目的相信,要有质疑精神,而是要自己去看数据,根据常识去提出假设,再来看数据是否验证了自己的假设。最后,我们还要想从数据中还能问出什么样的问题,好问题永远比好答案更有价值。